政策與議題

【Big Data】多國收集國民DNA 大數據與個資權利可否共存?
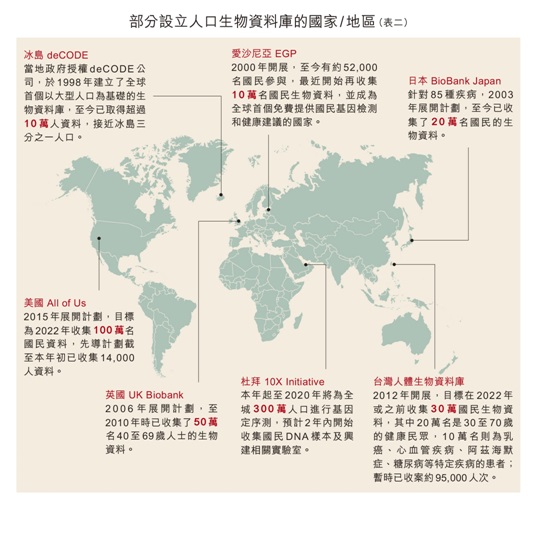
電子化國家先驅愛沙尼亞上周宣布,其生物資料庫(biobank)將在本月開展最新計劃,成為首個為國民免費提供基因檢測和健康建議的國家,從而收集10萬名國民的基因資料。不單止國家,近年不少藥廠和生物醫學公司亦紛紛籌建生物資料庫。到底生物資料庫有何潛力?要實行如此龐大的計劃,又要面對什麼困難?
愛沙尼亞並非唯一一個最近在人口(population-based)生物資料庫方面有所動作的國家。美國國家衞生研究院(NIH)的生物資料庫項目All of Us,亦會在本年春季正式招募100萬名國民志願者,包括不同種族、同性戀、雙性戀和跨性別人士等,進行基因組測序及取得醫療記錄和血液樣本。此外,杜拜在上月也宣布會在未來兩年啟動類似計劃,希望收集全市共300萬人口的生物樣本。
免費提供基因檔案或許很吸引,但資料通常很難闡釋,特別是與嚴重疾病風險相關的。參與者得到的可能是疑惑多於答案,甚至焦慮。
英國納菲爾德生物倫理會(UK Nuffield Council on Bioethics)總監韋濤(Hugh Whittall)對《新科學人》(New Scientist)說
基因研究促進建立人口生物資料庫
科學家收集及儲存人類樣本已有過百年歷史。所謂生物資料庫,泛指接收、儲存、處理生物樣本及其數據的設施或系統,但一般所指的都是人類的樣本,例如血液、細胞、基因樣本,生物資料庫有多種,按樣本的種類和目標來劃分(表一)。

過往研究基因疾病依據的不外乎病人的DNA樣本、病歷、族譜和家族病史,但隨着科學家發現基因疾病往往不是單一基因變異所引起,以往的做法愈來愈難了解基因疾病的成因,需要更大規模和更仔細地收集人群樣本及生活環境資料。隨着2003年人類基因組計劃(Human Genome Project)宣布,人類基因解碼及排序工作已基本完成,加上基因技術和資訊科技的進展,促使更多國家相繼成立了自己的大型人口生物資料庫(表二)。
大數據造就精準醫療潮流
這些大數據的最終目的是精準醫療(Precision Medicine)或個人化醫療(Personalized Medicine)。精準醫學最早由美國國家研究委員會(NRC)在2011年提出,除了用常規檢查及病人描述症狀等傳統診斷方法,還配以基因、蛋白質、代謝等生物醫學檢測,再將個人資料如性別、身高、體重、種族、個人病歷、家族病史等,透過生物資料庫比對及分析,以找出最適合病人的治療方法及藥物組合(drug cocktail)。
藥物治療素來以一體適用(one-size-fits-all)為原則,即罹患某種疾病的病患一律使用某種藥物。在這種模式下,超過九成藥物都在研發試驗過程中失敗,而推出市面的不同藥物中,平均高達約四成至七成半是無效的。生物資料庫的出現,長遠除可幫助國民更好地預防疾病,也促進新藥和疾病檢測的研發,改善公共衞生和社會福利,因此吸引了部分政府投入龐大資源。英國生物資料庫(UK Biobank)去年估算,完成50萬人基因定序的經費就需要約1.5億美元;而All of Us是美國前總統奧巴馬在2015年國情咨文中提出的「精準醫療計劃」,當時獲批2.15億美元成立,10年內將共撥款14.55億美元。
生技公司嫌政府慢 紛紛投資部署
然而,一些公司批評政府進展緩慢,紛紛擴張自家版圖。All of Us成立三年以來,連一個國民的基因定序都沒有做過,只有17,000名先導志願者提交了血液和尿液樣本、度高磅重及填了問卷。相比之下,美國生物技術公司再生元(Regeneron)至今已為10萬人進行基因定序。其主席揚科普洛斯(George Yancopoulos)就質疑:「以此進度,政府何時才達到100萬人的目標?納稅人又付出了什麼代價?」
本年1月,再生元更成功拉攏輝瑞(Pfizer)、阿斯特捷利康(AstraZeneca)等五間大藥廠,各注資1,000萬美元,以提早完成自家基因醫療資料庫,加快腳步開發新藥,從現時全球總值17,600億美元的個人化醫療市場分一杯羮。
保障知情還是製造恐慌?
生物資料庫貌似前景向好,但現時擁有enCODE的藥廠安進(Amgen),其研發副主席夏栢(Sean E. Harper)就提醒,分析數據的複雜程度難以想像。此外,在執行上亦要考慮倫理方面的問題。最常問的是:到底應不應向參與者透露其樣本的分析結果?
All of Us總監迪旭曼(Eric Dishman)曾用多種用法治療罕見腎癌不果,直到進行了基因組測序和分析後才發現同時患有另一種癌症,結果對症下藥得以痊癒。作為精準醫療的受惠者,迪旭曼認為參與者至少有權選擇知道自己的生物數據,並像他一樣用來改善健康。但他也預料總會有參與者不願意知道自己的基因數據,因此他較傾向一種分級制度。這正是愛沙尼亞現時的做法,例如參與者可以選擇只知道自己是否容易染上一些常見疾病,而不想知道癌症風險是否增加。
然而,畢竟不可能要求所有參與者都像他一樣,擁有足夠的知識水平。特別是一些基因疾病風險,由於不同基因交互作用複雜,以現有知識難以判定這些分析結果有多準確和重要。
英國生物資料庫曾經試驗,替參與者全身掃描,放射治療師若發現異常結果就會通知參與者及醫生。結果有20%參與者驗出異常,他們會因而做更多測試,甚至有人進行切除肺葉等大型開刀手術。但最後發現當中只有八分之一人確實有病。自此當局就放棄把樣本數據回饋予參與者。
惟步入資訊科技時代,「生物權利」(biorights)也如數據、網絡私隱之類日漸得到重視。明尼蘇達大學的法律、醫療與公共政策教授禾芙(Susan Wolf)預期,大眾將愈來愈擁抱開放的數據。
「科學家取樣後研究出對健康重要的數據,並拒絕回饋數據予大眾的那個年代,已經過去了。」
明尼蘇達大學的法律、醫療與公共政策教授禾芙(Susan Wolf)
無法確保知情同意
生物資料庫這種前瞻性的研究,大規模及長期收集數據供未來研究之用。這衍生出另一倫理上的兩難:參與者是否稱得上在知情同意的情況下捐贈生物樣本?既然這些數據在日後將會用作什麼用途也不確定,即使參與者在提供樣本前簽了同意書,也難以充分得知研究用途及風險。
針對這個問題,日本、瑞典、新加坡會就每一個新研究項目,再次向先前提交過樣本的參與者取得同意,但這可能令繁瑣程序大增,對參與者造成騷擾或額外的疑慮。英國、加拿大、挪威、愛沙尼亞、台灣等,則在參與者首次捐贈樣本時便同時為日後研究取得「概括同意」,參與者日後可隨時取消同意。
私隱把關成隱憂
不論生物資料庫將來如何使用,為樣本數據私隱把關將成為一大隱憂。從Facebook因劍橋分析(Cambridge Analytica)的醜聞而形象嚴重受損一事,可見在現今世代,不當處理個人私隱資料會令大眾對資訊科技公司的信任一瞬崩解。生物資料庫處理的資料遠比Facebook上的資料來得敏感,將會面臨更大的挑戰。一方面,生物資料庫的存在本身就是對私隱的一大威脅,即使經過匿名和編碼處理仍然有一定的辨識風險。另一方面,更重要的是參與者未必有權擁有自己捐贈的生物樣本。例如在英國,樣本的擁有權及知識產權屬於資料庫一方。
儘管面對這問題,生物資料庫與道德倫理之間不會是零和博弈,只是必須經過我們每一個參與討論,才有望真正帶來福祉,而非帶來更多不安。
上文節錄自第106期《香港01》周報(2018年4月9日)《生物資料庫:大數據與倫理博弈》。